




These days it’s obvious that the more we leverage artifical intelligence (AI) technology, like ChatGPT, the smarter and seemingly more self-reliant it becomes. And unfortunately, with these advancements, there’s also a higher risk of AI bias. It’s become increasingly clear that, just like humans, bots can develop bias related to various demographics such as race, gender, sexuality and disability.
In other words, AI can be influenced by our own personal biases and learned behaviors, no matter how unconscious or implicit these biases can be.
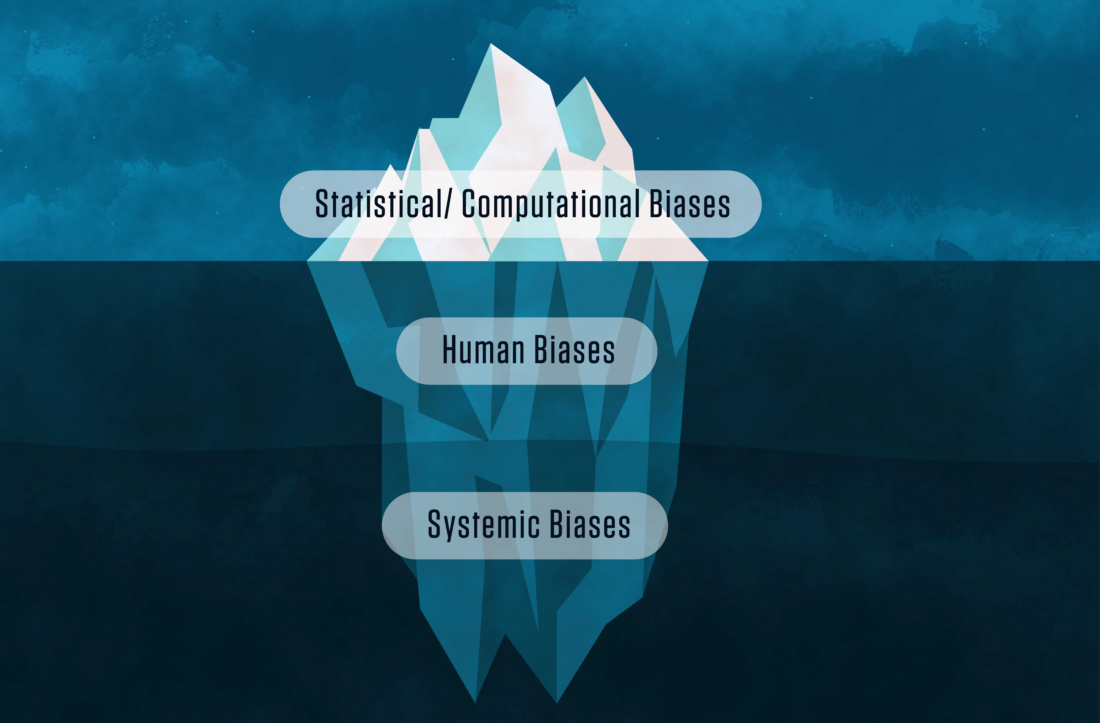
It’s the Algorithm
Algorithms are typically developed to solve a specific problem or task. One of the main steps in designing an algorithm is collecting and understanding the data. While it may seem straightforward enough to map out a process that produces a solution, there will always be nuances.
One significant problem in designing fair AI algorithms is the lack of access to data related to marginalized communities and populations. An algorithm on its own isn’t biased; it’s the data that we feed it. Without proper data, certain populations will be underrepresented, leading to skewed data, flawed predictive analytics, and the potential for algorithmic discrimination.
After the algorithm is developed, it should be tested internally and audited, possibly by an outside entity. Once the algorithm is implemented, it must be consistently monitored throughout its life cycle, especially if your team lacks the necessary diversity and alternate points of view to address the challenges.
It’s the Data
Another explanation for AI bias is the use of incomplete and/or inaccurate data. Comprehensive data is needed to avoid unintentional bias. The collection of data and data practices must be representative of all populations in order to ensure a more inclusive experience and fair AI model output. For example, what data is being used to train the model? Algorithmic bias, dataset bias, and cognitive bias are just a few instances that can result in discriminative results if access to relevant data is limited.
While people are aware of the issue of AI bias, confronting it is not a simple or singular task. A primary example of bias in AI is facial recognition, which has proven to be the least accurate biometric used in identification. A well-known study conducted by ProPublica in 2016 concluded that an AI algorithm being used at the time to predict recidivism among defendants was inherently biased against Black people.
That said, algorithmic discrimination is the most frequent issue impacting data sets. Is the data provided transparent? Is the lack of diversity in your company having a negative effect on the data you’re using? If that’s the case, soliciting the feedback of outside stakeholders can help counteract bias.
It’s Us
In the data decision making process, personal and cultural biases, along with basic subjectivity, can be extremely subtle. That’s one reason that employing a diverse team with many different experiences and points of view is so critical. Underrepresented people can identify biases that other people might not be aware of.
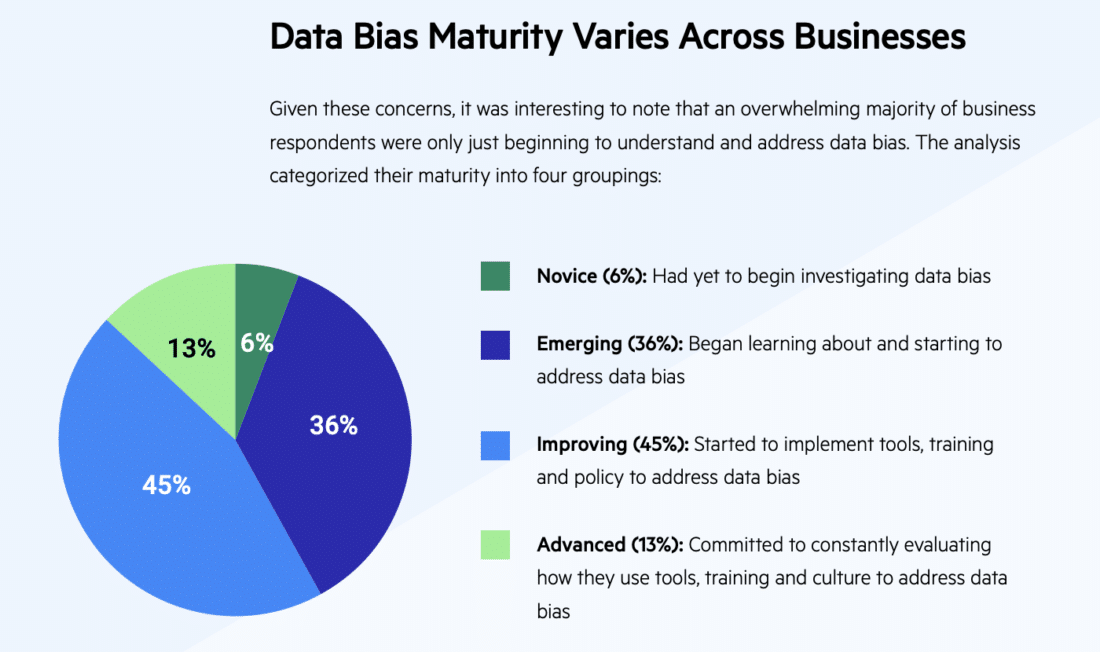
In a recent interview with BetaNews, Matthieu Jonglez, VP of Technology at software company Progress, pointed to research showing that two-thirds of organizations believe there is currently data bias in their process. Some of his suggestions for reducing this bias is to create a more robust data policy as well as mechanisms that measure bias. Jonglez also recommends building transparency into all AI use as “transparency is the antidote to bias.”
Human bias, from cognitive bias to categorization, will never be fully eradicated from AI. But there are a number of protective measures that can help including company diversity; fair data; and implementing a more thoughtful process relating to the use of AI technologies.
Ultimately AI learns through our unconscious bias and thought patterns, and responds accordingly. It’s up to us to address and mitigate this risk.
Image by Gerd Altmann
Join the conversation